核心论点
从 AlphaGo 到 ChatGPT 再到 DeepSeek R1,AI 的关键突破在于:摆脱人类反馈的枷锁,通过纯强化学习对齐客观真理,从而实现超越人类的可能。R1-Zero 是 DeepSeek 的 AlphaZero 时刻。
一、AlphaGo:突破人类上限
围棋 vs 国际象棋
| 维度 | 国际象棋(深蓝) | 围棋(AlphaGo) |
|---|---|---|
| 棋盘大小 | 8×8(64 格) | 19×19(361 点) |
| 平均每步合法走法 | 35 种 | 250 种 |
| 平均对局步数 | 80 步/局 | 150 步/局 |
| 状态空间复杂度 |
- 深蓝:暴力搜索,本质是”比人类快得多的计算器”
- AlphaGo: 远超超级计算机算力,必须依赖深度学习 + 蒙特卡洛树搜索
关键跃迁:AlphaZero
AlphaGo 用人类棋谱训练,但学习顶尖棋手只能接近、无法超越他们。AlphaGo 第 37 步被认为是”人类永远不会下的一步”——这来自强化学习自我对弈。
更进一步:AlphaZero 完全不需要人类棋谱,只告诉它规则,让模型自我对弈(赢了奖励、输了惩罚),就能从零学会围棋并超越人类。
核心启示
想要超越人类,必须让模型摆脱人类经验和偏好的限制。
为何 AlphaGo 没有改变世界?
围棋是规则明确、目标单一的封闭空间游戏。现实世界则是:开放空间、无限可能、没有确定目标、没有明确的成败判定、试错成本高。
二、ChatGPT:压缩即智能
三阶段训练
| 阶段 | 名称 | 做什么 |
|---|---|---|
| 1 | 预训练(Pre-Training) | 学习预测下一个字,在压缩中产生智能 |
| 2 | 监督微调(SFT) | 用人工构造的问答数据,学会人类问答模式 |
| 3 | RLHF | 用奖励模型训练,让输出符合人类偏好 |
大模型撞墙
- 数据耗尽:人类产生的数据在 2024 年底已被消耗殆尽,按 Chinchilla Scaling Laws,模型增大 10 倍需要 10 倍数据,但数据不够了
- RLHF 的天花板:普通人已无法评估模型输出,即便请专家,终究有一天最顶尖专家也无法评估
RLHF 不是 RL
RLHF 本质是讨好人类的训练方式。如果让李世石评价 AlphaGo 的第 37 步,他很可能给负分——AI 就永远无法逃出人类思维的枷锁。
— Andrej Karpathy:“强化学习(RL)很强大,但 RLHF 并不是 RL。“
三、DeepSeek R1-Zero:另一个 AlphaZero 时刻
核心方法
选择数学和代码作为训练数据——因为它们可以自动、客观地评估正确性(数学可验证推导,代码可编译运行)。
只对结果奖励(ORM),不对思考过程逐步打分(PRM),原因:
- 思考过程该分几步?不同任务不同
- 每一步正确性很难量化,有些”错误”思考反而启发正确方向
- 对过程打分可能导致 reward hacking(只专注于列公式得分而非真正解题)
GRPO 算法
以 2+3=? 为例
第一步:模型生成多个回答
- “5”
- “6”
- “<思考>2+3=5</思考><结果>5</结果>”
第二步:打分 → 1分、0分、2分
第三步:平均分 = 1
第四步:与平均分对比 → 0、-1、+1
第五步:强化学习,倾向于生成包含思维链、且结果正确的回答
训练中的涌现
虽然没有对输出长度奖励,但模型自发输出越来越长的思考过程——复杂问题需要更长的思考,这是自然涌现。
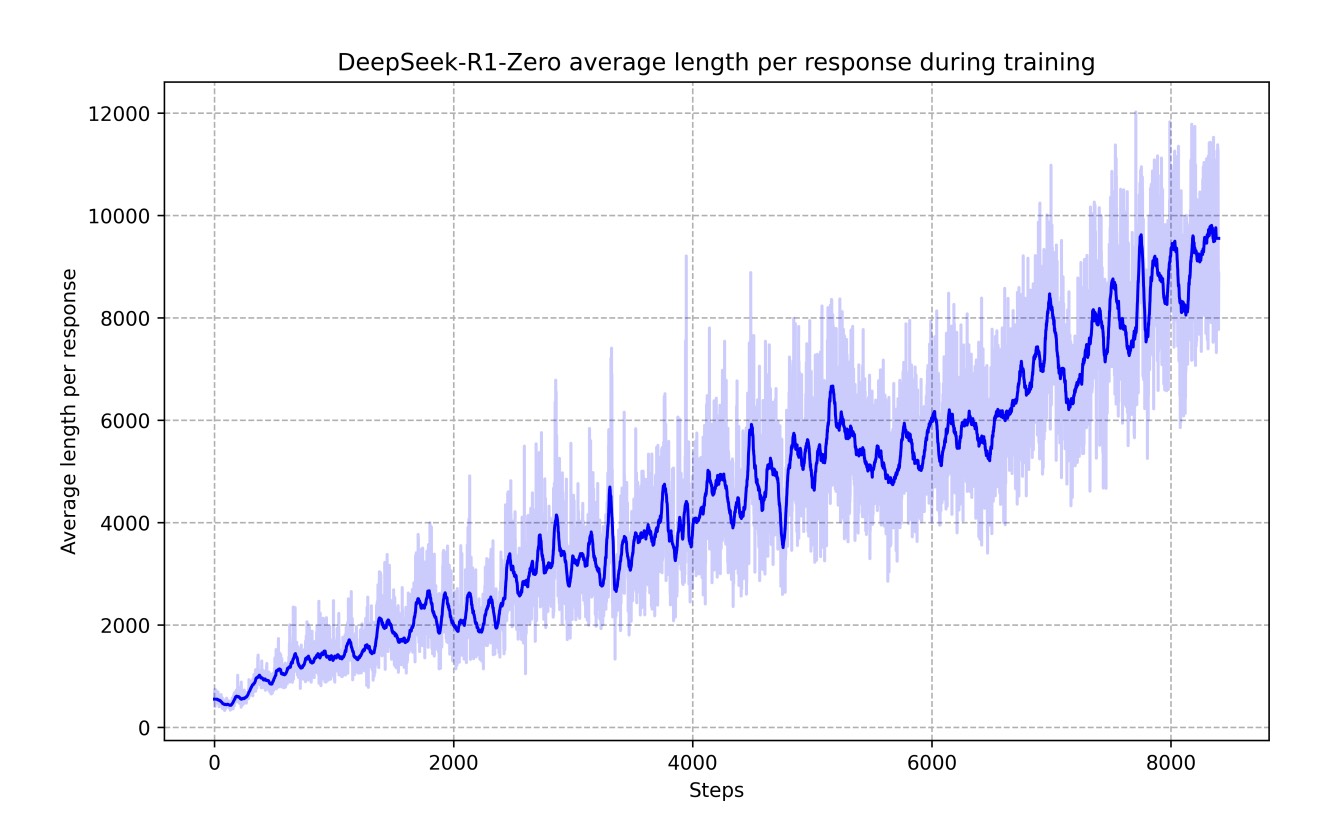
四、从 R1-Zero 到 R1
R1-Zero 虽然推理能力强,但没学过人类问答模式,且存在语言混合问题。DeepSeek 的解决方案:
SFT → RL → SFT → RL
| 步骤 | 目的 |
|---|---|
| 1. SFT(冷启动) | 少量高质量 CoT 数据,解决语言不一致 |
| 2. RL(推理训练) | 类似 R1-Zero 的纯 RL + 语言一致性奖励 |
| 3. SFT(通用能力) | 适应非推理任务(写作、事实问答等) |
| 4. RL(最终对齐) | 推理任务用 RL,写作任务用类 RLHF |
五、核心洞察
对齐人类品味 vs 对齐客观真理
| 维度 | 对齐人类品味 | 对齐客观真理 |
|---|---|---|
| 代表 | Suno(音乐)、Recraft(图像) | DeepSeek R1、AlphaZero |
| 评估方式 | 主观(人类满意度) | 客观(数学正确、代码运行) |
| 天花板 | 无法超越人类审美 | 可以超越人类认知 |
| 竞争方式 | 品味不会提升只会改变 | 榜单竞争残酷但有超越可能 |
认知链条
AlphaGo → 人类棋谱 + RL → 超越棋手但局限于围棋
AlphaZero → 纯 RL,无需棋谱 → 验证了"无需人类知识"的路线
ChatGPT → 预训练 + SFT + RLHF → 压缩产生智能,但受限于人类反馈
DeepSeek V3 → 同上路线,更高效 → 比肩 GPT-4o,成本仅 550 万美元
R1-Zero → 纯 RL,无需人类反馈 → 在推理任务上的 AlphaZero 时刻
R1 → R1-Zero + SFT 打磨 → 开源的、比肩 o1 的 Reasoning 模型
Quote
如果模型能根据直角三角形推导出勾股定理,我们有理由相信它终有一天,能推导出现有数学家尚未发现的定理。
六、常见误解澄清
| 误解 | 事实 |
|---|---|
| ”R1 是蒸馏 o1 的” | 蒸馏的学生模型几乎一定比老师差,但 R1 某些指标比 o1 更强 |
| ”R1 说自己是 ChatGPT,所以是套壳” | 模型不知道自己被谁训练,训练数据中包含”我是 ChatGPT”语料而已 |
| ”AI 会用聊天记录训练” | RL 模型只需高质量推理数据(数学/代码),普通聊天数据已不重要 |
| ”有多少人工就有多少智能” | R1-Zero 证明了几乎不需要人类反馈也能提升性能 |
参考资料
- Wikipedia: AlphaGo versus Lee Sedol
- Nature: Mastering the game of Go without human knowledge
- The New Yorker: ChatGPT is a blurry JPEG of the web
- Andrej Karpathy on RL vs RLHF
- Dario Amodei: On DeepSeek and Export Controls
- ggml: x2 speed for WASM by optimizing SIMD